

Advanced Editor
Full text editor based on Ace, to work on multiple projects. Requires Electron.
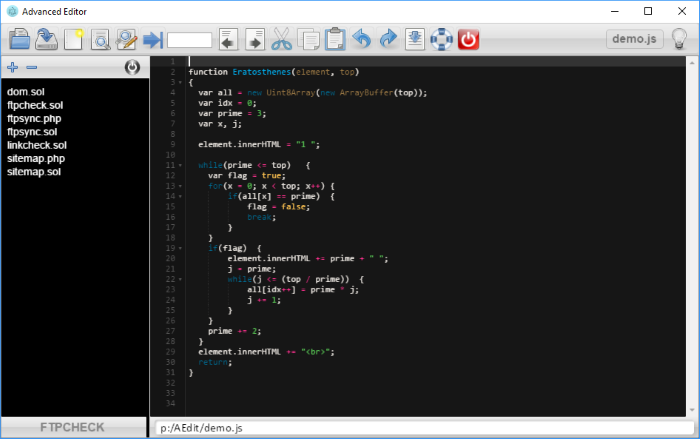
Advanced Editor is a programming editor especially designed to users like me who have to switch frequently between several projects.
It work locally with Electron.
Features
- All the classic functions of a code editor.
- Supports all popular programming languages, markdown and HTML.
- Load and save your code either in files, or in a database.
- Change project in one click.
- Many useful editing features. Example: juste type a line number in the input field and the code is displayed. Comment/uncomment in one click.
- Syntax highlighting for most programming languages.
- Syntax corrector.
- Automatic commenting and reactivation for C-like languages.
- Displays markdown code and HTML code like a web page.
Why a database?
The database you have created is easy to use in an application. It can be loaded on a web site with SQL.js and you can use functions and objects stored in the database if they are written in JavaScript or WebAssembly.
The database then works like a module, with the advantage you can change the content or add new functions dynamically. Your program can become evolutive, learn from its results and then modify its methods and replace them to the base
Install Advanced Editor
- Install Node.js.
- Go to the root of the drive and install Electron with this command:
npm install electron -g
- Download Advanced Editor and extract the contents.
- Create an icon on the desktop holding this command:
electron c:\AEditor\
The system will update the electron path. The working directory is that of AEditor. - Click on the icon to start the program.